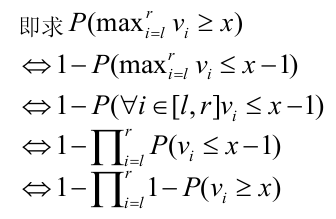搞颓记录
8-1 考了自己的题,结果T1锅了
T1 CF原题数据太水,导致我的假做法也能过
不过问题不太大,修改了一下就过了
8-2 Process T1搞了一个小时,后面在想T2的20分怎么做,以及T3的正解做法,均无果
Score 100 + 10 + 30 = 140
T1 [数据结构] [线段树]
每个点维护一个二进制标记,如果第i i i 1 1 1 i i i
修改的时候,因为至多只有首尾两层是不满的段,其他中间的段都是满的,因此中间的每次都是O ( 1 ) O(1) O ( 1 ) O ( n log n ) O(n\log n) O ( n log n )
修改不满的段的时候的做法比较巧妙,但也不难想,以后如果忘了看看代码就懂了。。。
T2 还没改,不知道会不会改
T3 [动态规划]
一个经典套路:忽略题意中的走的顺序,从左往右依次加点进行dp
那么原序列就会被分成若干个联通块(实际上是若干条链,这里暂且称作联通块),设d p [ i ] [ j ] dp[i][j] d p [ i ] [ j ] i i i j j j
Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 inline int left (int x) if (A[x] != 'R' ) return 1 ; return 0 ; }inline int right (int x) if (A[x] != 'L' ) return 1 ; return 0 ; }inline void Solve () memset (Dp, 0 , sizeof Dp); if (A[N] == 'R' && T != N) { puts ("0" ); return ; } Dp[N][0 ] = 1 ; for (int x = N - 1 ; x >= 1 ; --x) { for (int k = 0 ; k <= N; ++k) { int &ans = Dp[x][k]; if (x == S) { if (k && left (x)) Add (ans, (LL) k * Dp[x + 1 ][k - 1 ] % Mod); if (right (x)) Add (ans, Dp[x + 1 ][k]); } else if (x == T) { if (k) Add (ans, (LL) k * Dp[x + 1 ][k - 1 ] % Mod); Add (ans, Dp[x + 1 ][k]); } else { if (left (x)) { if (k >= 2 ) Add (ans, (LL) k * (k - 1 ) % Mod * Dp[x + 1 ][k - 1 ] % Mod); if (k && x > S) Add (ans, (LL) k * Dp[x + 1 ][k - 1 ] % Mod); if (x > T) { if (k) Add (ans, (LL) k * Dp[x + 1 ][k - 1 ] % Mod); Add (ans, Dp[x + 1 ][k]); } Add (ans, (LL) k * Dp[x + 1 ][k] % Mod); } if (right (x)) { Add (ans, Dp[x + 1 ][k + 1 ]); if (x > S) Add (ans, Dp[x + 1 ][k]); Add (ans, (LL) k * Dp[x + 1 ][k] % Mod); } } } } printf ("%d\n" , Dp[1 ][0 ]); }
8-3 上午听zjm讲组合,生成函数,多项式;下午听zqc讲容斥反演
似乎迷迷糊糊听懂了一点,可是理解还是不够
8-4 Process cxr的题,T1傻逼题居然没想到,自闭了自闭了
就写了T1 T3两个暴力,根本没开T2,后来改题的时候看T2发现好像也不太难
60 + 0 + 60 = 120
T1 真的是sb题
考虑把答案设为根,此时会有一些限制不满足,又因为一定在根的子树中,那么设d i d_i d i i i i d i d_i d i d i d_i d i x x x x x x
T2 [强连通分量] [缩点] [组合数学] [范德蒙德卷积]
题解很清楚
第二部分中,我们假设所有在A A A A A A
第二部分中x x x A A A c n t 1 + x + 1 ≤ A cnt1 + x + 1 \le A c n t 1 + x + 1 ≤ A ∑ x ( c n t 2 x ) ( c n t 1 B − 1 − x ) \sum_{x}\binom{cnt2}{x}\binom{cnt1}{B-1-x} ∑ x ( x c n t 2 ) ( B − 1 − x c n t 1 ) ( c n t 1 + c n t 2 B − 1 ) \binom{cnt1 + cnt2}{B-1} ( B − 1 c n t 1 + c n t 2 )
T3 没改
8-5 Process T3模板题, T1花了点时间推式子,T2傻逼dp居然都没想到(最后时间不太够,有点急)
100 + 30 + 100 = 230
T1 [数学]
设a , b , c , d a, b, c, d a , b , c , d ( 0 , 0 ) , ( 0 , 1 ) , ( 1 , 0 ) , ( 1 , 1 ) (0, 0), (0, 1), (1, 0), (1, 1) ( 0 , 0 ) , ( 0 , 1 ) , ( 1 , 0 ) , ( 1 , 1 )
设a 1 , b 1 , c 1 , d 1 a_1, b_1, c_1, d_1 a 1 , b 1 , c 1 , d 1 a 2 , b 2 , c 2 , d 2 a_2, b_2, c_2, d_2 a 2 , b 2 , c 2 , d 2
可以列出一些方程,手解一下就行
最后化出来一步b 1 + c 1 = t b_1 + c_1 = t b 1 + c 1 = t b 1 = min { b , t } b_1 = \min\{b, t\} b 1 = min { b , t } c 1 c_1 c 1
T2 [动态规划] [数据结构] [线段树] [单调栈]
设d p [ i ] dp[i] d p [ i ] i i i
d p [ i ] = min j { d p [ j ] + max k = j + 1 i } + ∑ j = i + 1 n w j
dp[i] = \min_{j}\{dp[j] + \max_{k=j + 1}^{i}\} + \sum_{j=i + 1}^{n}w_j
d p [ i ] = j min { d p [ j ] + k = j + 1 max i } + j = i + 1 ∑ n w j 单调栈 + 线段树维护一下max \max max
类似于19-6-22 T1
T3 [图论] [网络流] [欧拉回路]
混合图欧拉回路模板题
今天晚上想搞一点zjm课件的题
8-6 讲课,拖堂了1个小时
讲得有点累,幸好把话筒修好了,不然可能会当场去世
晚上把zjm的组合题搞完了
8-7 Process 今天整个不在状态。一个sbT2还想了一两个小时。
T1想了个乱搞,没搞出来。T3没怎么仔细想,结果爆零了
最后T2还因为没卡常爆成40
10 + 40 +0 = 50
T1 [动态规划] [搜索]
枚举每个点作为起点搜索 , 设 d p [ i ] [ j ] [ k ] dp[i][j][k] d p [ i ] [ j ] [ k ] ( i , j ) (i,j) ( i , j ) k k k
如何记录是否吃到了某个豆子呢 ?
当蛇在豆子的右边穿过奇数次时就能包围住 , 穿过偶数次就没有包围住.
预处理一下经过某个点后,豆子是否被选中这个状态如何改变即可
T2\ [二分答案]
二分答案,差分check
这里必须要加一个优化:不要每次都从1到mid去算答案,而是类似于一个指针在上面移动,维护上次check到这次check中间的变化量
T3 [动态规划] [组合数学] [容斥]
不难发现,每行填的数都是一个排列去掉一个数
枚举这个断点即可得到O ( n 3 ) O(n^3) O ( n 3 ) O ( n 2 ) O(n^2) O ( n 2 )
设d p [ i ] [ j ] dp[i][j] d p [ i ] [ j ] i i i j j j
d p [ i ] [ j ] = d p [ i − 1 ] [ j + 1 ] + d p [ i ] [ j − 1 ]
dp[i][j] = dp[i - 1][j + 1] + dp[i][j - 1]
d p [ i ] [ j ] = d p [ i − 1 ] [ j + 1 ] + d p [ i ] [ j − 1 ] 结合这里 的图可以发现,答案就是从原点出发,只能向右或向上走,不接触直线A,B,到达点( n + m + 1 , n ) (n+m+1,n) ( n + m + 1 , n )
考虑容斥,先算从原点到( n + m + 1 , n ) (n + m + 1, n) ( n + m + 1 , n ) A , B A, B A , B
考虑将终点p p p A A A p ′ p' p ′ p ′ p' p ′ 碰到A至少一次的方案数
同理,关于B B B 碰到B至少一次的方案数
显然这样又会算重,算重的情况是先碰到A,然后碰到B,或者先碰到B,然后碰到A
也就是碰到边界的序列中存在AB或BA子序列的方案
于是又可以继续对称,把终点先关于B B B A A A AB的方案
以此类推
不难发现容斥系数为( − 1 ) c n t (-1)^{cnt} ( − 1 ) c n t c n t cnt c n t
模拟求解即可,对称到不在第一象限时就停止。最多对称log \log log
19.10.6 UPD
之前可能还是没太搞清楚
显然,总方案去掉经过A A A 或 B B B
如何保证一种经过A A A
把终点p p p A A A p ′ p' p ′ p ′ p' p ′ 至少经过一次 A A A
但这样算是错的,因为子序列A B AB A B A A A B B B B A BA B A
所以要加上经过子序列
、
的情况(终点依次关于
、
对称
但子序列A B A ABA A B A
、
减一次,被
、
加一次),必须要再减一次;B A B BAB B A B
注意,此时A B B ABB A B B
、
减一次,被A B AB A B − 1 -1 − 1
以此类推
8-8 Process T1花了半个小时,然后一直在搞T2。T2完全没有想到分治,一直在往扫描线的方向去想,始终无果
T1 见GC's Blog
T2 [分治]
统计序列中点对的问题要往分治上想!!!
考虑跨区间的贡献!!!
想到分治后不难
题解写得还可以
T3 [动态规划]
最后需要找到一个t t t ∑ i = 1 n _ _ b u i l t i n _ p o p c o u n t ( t + m x − a [ i ] ) \sum_{i=1}^{n}\_\_builtin\_popcount(t + mx - a[i]) ∑ i = 1 n _ _ b u i l t i n _ p o p c o u n t ( t + m x − a [ i ] )
可以考虑t t t
暴力dp需要知道当前位往下一位有哪些数进了位
但是不难发现,若一个数前i − 1 i-1 i − 1 i i i
那么根据这个性质每次将数排序后,进位的数就是一段前缀了
具体细节可见Sol/Code
8-9 上午xz讲数据结构,下午jwb讲线段树
今天有点晕,不想接受新的东西。。。就水过去了
有时间搞下jwb的课件
8-10 Process 开场想了下T1,无果。然后发现T2很sb,写完之后去看T3,发现一个很直观很暴力的线段树合并做法。
T3调到考试结束前半个小时,最后慌慌张张写T1暴力,结果部分分写挂了
最后T2也挂了20分。。。
35 + 80 + 100 = 215
T1 [图论] [边双]
转化为求多少点对之间存在至少d d d
若联通:至少1条
若在同一个边双中:至少2条
若把图中任意一条边删除后,它们仍在同一边双中:3条
第三种情况枚举删哪条边即可
T2 转化为求
的( x , y ) (x, y) ( x , y ) y l yl y l y y y
枚举x x x y l yl y l m a p map m a p y y y
T3 [数据结构] [线段树] [线段树合并]
我的暴力线段树合并做法:
对于一个询问x , k x, k x , k x x x max ≤ k \max\le k max ≤ k x x x
维护一个权值线段树,下标是边权离散化之后的值,权值是每个边权对应的答案和
显然子树的限制可以通过线段树合并来解决
而对于一条权值为d d d ≤ d \le d ≤ d d d d max \max max
直接在线段树上区间查,区间置0 0 0
晚上搞了TJOI2015旅游和xsy1599A
8-11 Process 倒序做题,T1写了个斜率优化(差不多又快忘光了。。。)
50 + 100 + 100 = 250
T1 [动态规划] [斜率优化]
有一个性质没挖掘出来:
若钦定某个点在最优策略里被选,那么策略与它的值没有关系
剩下的看sol吧
用分治优化dp,同时用上斜率优化
T2 [贪心] [最小生成树]
贪心最小生成树
每个点只往它当前这一列的相邻点,以及另一列离它最近的两个点连边即可
T3 随便dp一下,处理出每个点到根的最短路
晚上把AGC028D搞完了,然后发现斜率优化学得狗屎样的,重新学了下
8-12 上午的贪心好神啊。。。
下午图论听了一部分
今天的课件都要找时间搞了
晚上搞了NOI2019D1T1和「LNOI2014」LCA
8-13 Process 前两题搞完的时候是10:40,太慢了。。。T2写了半天
T3写了个暴力,搞链的分但是做法有点问题
T1 题解很清楚
我直接找的规律,规律很好找
T2 [数据结构]
我的做法和k k k k k k
也可以CDQ分治,做到与k k k
T3 [动态规划] [组合数学]
在a a a b b b d p [ i ] [ j ] dp[i][j] d p [ i ] [ j ] i i i j j j
每次把点往前面的方案里插即可
对组合数的理解的应用还要再深一点
8-14 Process 想了一上午T1,不会做,期间想了一个假做法,以及推了下T2的式子,太麻烦就弃了
于是爆零了
0 + 0 + 0 = 0
T1 离散化之后就可以考虑每个单位格子 对答案的贡献!!!
怎么这么sb都想不到
我想的做法是n 2 n^2 n 2
考虑单位格子的话就不存在各种奇奇怪怪的问题了!!!
T2 [概率和期望] [线段树]
做法来自xcy
考虑[ L , R ] [L, R] [ L , R ] w i ∗ E ( i ) w_i * E(i) w i ∗ E ( i ) E ( i ) E(i) E ( i ) i i i
设a = ∏ j = i R p j \displaystyle a = \prod_{j=i}^{R}p_j a = j = i ∏ R p j
E ( i ) = a + 2 × ( 1 − a ) ⋅ a + 3 × ( 1 − a ) 2 ⋅ a + . . . = ∑ k = 0 ∞ ( k + 1 ) ( 1 − a ) k a = 1 a
\begin{aligned}
E(i) &= a + 2 \times(1-a)\cdot a + 3\times (1-a)^2 \cdot a + ...\\
&=\sum_{k=0}^{\infty}(k + 1)(1-a)^ka\\
&=\frac{1}{a}
\end{aligned}
E ( i ) = a + 2 × ( 1 − a ) ⋅ a + 3 × ( 1 − a ) 2 ⋅ a + . . . = k = 0 ∑ ∞ ( k + 1 ) ( 1 − a ) k a = a 1 于是答案就是∑ i = L R w i ∏ j = i R p j \displaystyle \sum_{i=L}^{R}\frac{w_i}{\prod_{j=i}^{R}p_j} i = L ∑ R ∏ j = i R p j w i
线段树每个结点维护一下w i ∏ j = i R p j \displaystyle \frac{w_i}{\prod_{j=i}^{R}p_j} ∏ j = i R p j w i ∏ j = i R p j \displaystyle {\prod_{j=i}^{R}p_j} j = i ∏ R p j
最后把n n n
T3 [LCT]
思路:
对每种权值维护一棵树,每个结点有黑白两种颜色,白色表示这个点是当前这种权值,黑色表示不是
那么答案就是所有操作之后,每个黑色联通块的s i z e 2 size^2 s i z e 2
用LCT维护即可
计算答案的时候先初始化一个全是黑点的树,离线处理每个颜色,处理完一个颜色反着改回去
类似于CDQ分治时清空BIT的方法
具体实现见此 ,或出题人sol
8-15 神仙讲课
晚上搞了两道gc的课件
8-16 Process 刚了一上午的T2
60 + 100 + 20 = 180
T1 [动态规划] [计数]
求整数分拆的方案数
先考虑两种dp
f [ i ] [ j ] f[i][j] f [ i ] [ j ] i i i j j j
转移考虑是否加上一个权值为j j j
g [ i ] [ j ] g[i][j] g [ i ] [ j ] i i i j j j
转移考虑把当前所有数+ 1 +1 + 1 1 1 1
注意到,f f f g g g
又因为权值大于n \sqrt n √ n n \sqrt n √ n f f f g g g n \sqrt n √ n
这里要把g g g j j j > n > \sqrt n > √ n
令m = n m = \sqrt n m = √ n
a n s = ∑ i = 0 n ( ∑ j = 0 m g [ i ] [ j ] ) × f [ n − i ] [ m ]
ans = \sum_{i=0}^{n}\Big(\sum_{j=0}^{m}g[i][j]\Big) \times f[n - i][m]
a n s = i = 0 ∑ n ( j = 0 ∑ m g [ i ] [ j ] ) × f [ n − i ] [ m ] T2
定义计算括号序列为将( ( ( + 1 +1 + 1 ) ) ) − 1 -1 − 1
我的做法比较暴力
首先考虑把所有? ? ? ( ( ( a a a
若某个合法的括号序列以i i i j j j i i i j j j
形式化地说,需要满足min k = i j a j − a i − 1 ≥ 0 \displaystyle \min_{k = i}^{j}a_j - a_{i - 1} \ge 0 k = i min j a j − a i − 1 ≥ 0
显然,这个式子具有单调性,即合法的右端点一定在区间[ i , R i ] [i, R_i] [ i , R i ] R i R_i R i
同理,把? ? ? ) ) ) L i L_i L i i i i [ L i , i ] [L_i, i] [ L i , i ]
一个小结论:只要满足[ i , R i ] [i, R_i] [ i , R i ] [ L i , i ] [L_i, i] [ L i , i ]
考虑枚举右端点i i i j ∈ [ L i , i ] j\in[L_i, i] j ∈ [ L i , i ] R j ≥ i R_j \ge i R j ≥ i
这个随便用个数据结构维护一下即可
T3 [线段树] [树链剖分]
8-17 gc的题,我验的题
T1 [组合数学]
补集转化,然后用插板法算下方案数即可
T2 [单调栈] [线段树]
先处理出关于c i c_i c i
按v i v_i v i
从那个位置开始把一段前缀减掉,用线段树维护即可
T3 把点权拆到边权上,每次考虑一个点把之前的哪个点作为父亲最优
显然只要考虑它到原树的根的那条链上的点即可,因为其他点都不会更优
晚上打了百度之星初赛
T2贪心没搞出来,没进250。。。
8-18 上午csy讲字符串,有一两道题断了
下午xcy讲树,基本还在线
晚上打了百度之星初赛第二场
抄了GC的T4,最后排名77
8-19 Process 似乎现在在考的是去年纪中的题了
T1还没想清楚细节就开始码,导致浪费了很多时间,最后只能交个log 2 \log^2 log 2
T2考过很多次了,结果遇到的时候还话了不少时间才看出来是那个模型。。。
T3没时间了,暴力没调出来(实际上是看漏了个条件)
Summary 现在开始的模考一定要认真对待!!!
每道题先写好暴力,想正解/码正解的题一定要掐好时间,不能出现暴力分没写完,甚至是有题爆零的情况!!!
T1 改了个好多细节的做法
二分某一个数组的下标,那么可以计算出另外一个数组期望的下标
再通过判断两个数组某些位置上的值的大小关系判断往左还是往右走
T2 d p [ i ] = max j = 0 i − 1 d p [ j ] + f ( min k = j + 1 i a k )
dp[i] = \max_{j=0}^{i-1}dp[j] + f(\min _{k=j+1}^{i}a_k)
d p [ i ] = j = 0 max i − 1 d p [ j ] + f ( k = j + 1 min i a k ) 和这天 一模一样
T3 [概率和期望]
首先有一个式子:对于一个随机变量x x x E ( x ) = ∑ i = 1 ∞ P ( x ≥ i ) \displaystyle E(x)= \sum_{i=1}^{\infty}P(x\ge i) E ( x ) = i = 1 ∑ ∞ P ( x ≥ i )
根据期望的线性性把式子拆开,考虑每个比x x x i i i
接下来对每个询问[ l , r ] [l, r] [ l , r ] x x x
也就是说,我们只需要求出[ l , r ] [l, r] [ l , r ] ≥ x \ge x ≥ x ( P ( v i ≥ x ) ) \big(P(v_i\ge x)\big) ( P ( v i ≥ x ) )
它就是小于x x x
然后考虑x x x y y y x x x
显然,最外面的1-可以最后计算,于是可以只考虑∏ i = l r 1 − P ( v i ≥ x ) \displaystyle \prod_{i=l}^{r}1 - P(v_i\ge x) i = l ∏ r 1 − P ( v i ≥ x ) 1 − P ( v i ≥ y ) 1 - P(v_i\ge y) 1 − P ( v i ≥ y ) 1 − P ( v i ≥ x ) 1 - P(v_i\ge x) 1 − P ( v i ≥ x )
但是这样做当P ( v i ≥ x ) = 1 P(v_i\ge x) = 1 P ( v i ≥ x ) = 1 P ( v i ≥ x ) P(v_i \ge x) P ( v i ≥ x ) x x x
即若∃ x > y , P ( v i ≥ x ) = 1 \exists x> y, P(v_i\ge x) = 1 ∃ x > y , P ( v i ≥ x ) = 1 P ( v i ≥ y ) = 1 P(v_i\ge y) = 1 P ( v i ≥ y ) = 1
所以从大到小枚举x x x
最后考虑多组询问如何处理
因为所给区间互不包含,所以每个点被包含的区间也是一个区间
只需要把答案的这段区间直接乘上当前的贡献,线段树维护即可
看代码可能更好理解。。。
Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 #include <bits/stdc++.h> #define x first #define y second #define y1 Y1 #define y2 Y2 #define mp make_pair #define pb push_back #define DEBUG(x) cout << #x << " = " << x << endl; using namespace std ;typedef long long LL;typedef pair <int , int > pii;template <typename T> inline int Chkmax (T &a, T b) return a < b ? a = b, 1 : 0 ; }template <typename T> inline int Chkmin (T &a, T b) return a > b ? a = b, 1 : 0 ; }template <typename T> inline T read () T sum = 0 , fl = 1 ; char ch = getchar(); for (; !isdigit (ch); ch = getchar()) if (ch == '-' ) fl = -1 ; for (; isdigit (ch); ch = getchar()) sum = (sum << 3 ) + (sum << 1 ) + ch - '0' ; return sum * fl; } inline void proc_status () ifstream t ("/proc/self/status" ) ; cerr << string (istreambuf_iterator <char > (t), istreambuf_iterator <char > ()) << endl ; } const int Maxn = 2e5 + 100 ;const int Mod = 1e9 + 7 ;namespace MATH{ inline void Add (int &a, int b) if ((a += b) >= Mod) a -= Mod; } inline int Pow (int a, int b) { int ans = 1 ; for (int i = b; i; i >>= 1 , a = (LL) a * a % Mod) if (i & 1 ) ans = (LL) ans * a % Mod; return ans; } } using namespace MATH;int N, M, Q;struct info { int x, y, p; } A[Maxn]; pii B[Maxn]; stack <int > stk[Maxn];int base[Maxn];int L[Maxn], R[Maxn];inline int cmp (info a, info b) return a.y < b.y; }inline int cmp_x (pii a, pii b) return a.x < b.x; }inline int cmp_y (pii a, pii b) return a.y < b.y; }namespace SEG{ #define mid ((l + r) >> 1) #define ls o << 1 #define rs o << 1 | 1 #define lson ls, l, mid #define rson rs, mid + 1, r struct info { int sum, tag; info () { sum = 0 , tag = 1 ; } } node[Maxn << 2 ]; inline void push_up (int o) inline void push_down (int o) { if (node[o].tag == 1 ) return ; node[ls].sum = (LL) node[ls].sum * node[o].tag % Mod; node[rs].sum = (LL) node[rs].sum * node[o].tag % Mod; node[ls].tag = (LL) node[ls].tag * node[o].tag % Mod; node[rs].tag = (LL) node[rs].tag * node[o].tag % Mod; node[o].tag = 1 ; } inline void build (int o, int l, int r) { if (l == r) return void (node[o].sum = 1 ); build (lson), build (rson); push_up (o); } inline void update (int o, int l, int r, int x, int y, int val) { if (x > y) return ; if (x <= l && r <= y) { node[o].sum = (LL) node[o].sum * val % Mod; node[o].tag = (LL) node[o].tag * val % Mod; return ; } push_down (o); if (x <= mid) update (lson, x, y, val); if (y > mid) update (rson, x, y, val); push_up (o); } inline int query () return node[1 ].sum; } #undef mid } inline void Calc (int x) int pre = 1 - (stk[x].top() - base[x]) % Mod + Mod; stk[x].pop(); int now = 1 - (stk[x].top() - base[x]) % Mod + Mod; SEG :: update (1 , 1 , Q, L[x], R[x], (LL) now * Pow (pre, Mod - 2 ) % Mod); } inline void Init () sort (A + 1 , A + M + 1 , cmp); for (int i = 1 ; i <= N; ++i) stk[i].push (1 ); for (int i = 1 ; i <= M; ++i) { int res = stk[A[i].x].top(); stk[A[i].x].push ((LL) res * (1 - A[i].p + Mod) % Mod); } for (int i = 1 ; i <= N; ++i) base[i] = stk[i].top(); sort (B + 1 , B + Q + 1 ); for (int i = 1 ; i <= N; ++i) { L[i] = lower_bound (B + 1 , B + Q + 1 , mp (0 , i), cmp_y) - B; R[i] = upper_bound (B + 1 , B + Q + 1 , mp (i, 0 ), cmp_x) - B - 1 ; } SEG :: build (1 , 1 , Q); } inline void Solve () Init (); int ans = 0 , i = M; while (i) { int j = i; while (A[j].y == A[i].y && j >= 1 ) Calc (A[j].x), --j; Add (ans, (LL) SEG :: query () * (A[i].y - A[j].y) % Mod); i = j; } ans = ((LL) Q * A[M].y % Mod - ans + Mod) % Mod; cout << ans << endl ; } inline void Input () N = read<int >(), M = read<int >(), Q = read<int >(); for (int i = 1 ; i <= M; ++i) A[i].x = read<int >(), A[i].y = read<int >(), A[i].p = read<int >(); for (int i = 1 ; i <= Q; ++i) B[i].x = read<int >(), B[i].y = read<int >(); } int main () freopen("max.in" , "r" , stdin ); freopen("max.out" , "w" , stdout ); Input (); Solve (); return 0 ; }
8-20 Process 又看错题。。。T2算方案数的时候看成当且仅当a i a_i a i
T1想错了一个地方,以为m m m 1 0 6 10^6 1 0 6
T3比较简单,直接矩阵快速幂即可
T1 [贪心] [动态规划]
显然对于相同体积的物品只用留权值最大的
暴力是O ( 1 0 0 m ) O(100m) O ( 1 0 0 m ) m m m m m m 1 0 6 10^6 1 0 6
T2 [卡特兰数]
第一问用后半部分减去前半部分
第二问奇偶部分相减
第三问括号序列,直接卡特兰数
T3 [容斥] [矩阵快速幂]
暴力容斥,然后矩阵快速幂算方案数
8-21 上午sxy讲课,又复习了下往年联赛题
下午自己在搞xcy课件
8-22 Process 刚了一上午T2,就没时间了
T1 [组合数学] [容斥]
把n n n m m m k k k [ 1 , m − 1 ] [1, m-1] [ 1 , m − 1 ]
设第一部分为i m im i m n − i m n-im n − i m
因为k k k [ 1 , m − 1 ] [1, m-1] [ 1 , m − 1 ] [ k , k ( m − 1 ) ] [k, k(m-1)] [ k , k ( m − 1 ) ] n − i m ∈ [ k , k ( m − 1 ) ] n-im\in[k, k(m-1)] n − i m ∈ [ k , k ( m − 1 ) ]
于是就可以枚举所有i i i
第一部分可以直接插板法算,是( i + k − 1 k − 1 ) \displaystyle \binom{i + k - 1}{k - 1} ( k − 1 i + k − 1 )
第二部分需要容斥,枚举有多少个数不合法(大于m − 1 m-1 m − 1 ∑ i = 0 k ( − 1 ) i ( k i ) ( ( n − i m ) − i ( m − 1 ) − 1 k − 1 ) \displaystyle \sum_{i=0}^{k}(-1)^i\binom{k}{i}\binom{(n-im)-i(m-1)-1}{k-1} i = 0 ∑ k ( − 1 ) i ( i k ) ( k − 1 ( n − i m ) − i ( m − 1 ) − 1 )
T2 [点分治]
点分治,然后数点
看上去需要二维数点,但是可以通过把某一维排序后降到一维
排序后不一定保证数出来的点分属两个不同的子树,于是需要把每个子树的答案减去
这应该是点分治的一个经典技巧,大概是这个意思:
1 2 3 4 5 6 7 8 9 10 Add (ans, process (x, A[x], A[x])); for (int i = Begin[x]; i; i = Next[i]){ int y = To[i]; if (Vis[y]) continue ; Add (ans, Mod - process (y, A[x], A[x])); divide (y); }
T3 [毒瘤]
不是sol的做法
考虑询问的x x x y y y m i d mid m i d m i d mid m i d x x x l c a lca l c a
答案由几部分取max构成:
l c a lca l c a
l c a lca l c a x x x y y y
x , y x, y x , y
设l a c k [ i ] lack[i] l a c k [ i ] f a [ i ] fa[i] f a [ i ] i i i
x x x m i d mid m i d i i i l a c k [ i ] + d i s ( f a [ i ] , x ) lack[i] + dis(fa[i], x) l a c k [ i ] + d i s ( f a [ i ] , x )
y y y l c a lca l c a i i i l a c k [ i ] + d i s ( f a [ i ] , y ) lack[i] + dis(fa[i], y) l a c k [ i ] + d i s ( f a [ i ] , y )
m i d mid m i d l c a lca l c a i i i l a c k [ i ] + d i s ( f a [ i ] , y ) lack[i] + dis(fa[i], y) l a c k [ i ] + d i s ( f a [ i ] , y )
前面三种情况随便处理
第四种情况把d i s dis d i s l a c k [ i ] − d e p [ f a [ i ] ] lack[i] - dep[fa[i]] l a c k [ i ] − d e p [ f a [ i ] ]
第五种情况同理
剩下就是一些细节
8-23 Process T1写了一早上,结果看错题了,是个分块模板题
后面又没时间搞了
T1 [分块]
直接分块,暴力维护答案,搞个tag就可以了
T2 f f f
T3 [概率和期望] [动态规划] [矩阵快速幂]
好神仙的概率期望
最难理解的地方是dp转移分母那里
和贝叶斯长得很像,但是感觉还是没完全理解。。。
8-25 Process T1就是暴力,随便写了下
T2猜结论,推了下性质搞出来了
后面由于某些特殊原因没怎么搞了
T1 暴力
T2 sol写得挺好
观察性质,猜结论,转化成坐标系中的经典问题
T3 sol写得挺好,看subtask3和subtask6
8-26 Process 搞了一上午T3,搞出来了,T2暴力写挂了
T1 若后手存在两个王,则先手胜,否则后手胜
T2 [分治]
因为操作可逆,显然可以把A , B A, B A , B
考虑归并排序,然后考虑如何把两个已经排好序的区间合并
假设考虑到[ l , m i d ] [l, mid] [ l , m i d ] [ m i d + 1 , r ] [mid + 1, r] [ m i d + 1 , r ]
那么从m i d mid m i d x x x A [ m i d − x + 1 ] > A [ m i d + x ] A[mid - x + 1] > A[mid + x] A [ m i d − x + 1 ] > A [ m i d + x ]
然后把[ m i d − x + 1 , m i d ] , [ m i d + 1 , m i d + x ] , [ m i d − x + 1 , m i d + x ] [mid - x + 1, mid],[mid + 1, mid + x],[mid - x + 1, mid + x] [ m i d − x + 1 , m i d ] , [ m i d + 1 , m i d + x ] , [ m i d − x + 1 , m i d + x ]
那么此时[ l , m i d ] [l, mid] [ l , m i d ] [ m i d + 1 , r ] [mid + 1, r] [ m i d + 1 , r ] [ l , m i d ] [l, mid] [ l , m i d ] [ m i d + 1 , r ] [mid + 1, r] [ m i d + 1 , r ]
T3 [动态规划] [计数]
考虑一个个往后填颜色,设f [ i ] [ j ] [ k ] f[i][j][k] f [ i ] [ j ] [ k ] i i i j j j j j j k k k
这是类似于一个栈一样的东西
比如如果填了1 2 3 4 3,那后面就不能填4了
可以先钦定一个排列顺序,最后乘上排列数
f [ i ] [ j ] [ k ] → f [ i + 1 ] [ j + 1 ] [ k + 1 ] f[i][j][k]\rightarrow f[i + 1][j + 1][k + 1] f [ i ] [ j ] [ k ] → f [ i + 1 ] [ j + 1 ] [ k + 1 ]
f [ i ] [ j ] [ k ] → f [ i + 1 ] [ j ] [ l ] , l ∈ [ 0 , k ] f[i][j][k] \rightarrow f[i + 1][j][l], l\in [0, k] f [ i ] [ j ] [ k ] → f [ i + 1 ] [ j ] [ l ] , l ∈ [ 0 , k ]
填表法,那么第二个转移就是一段后缀了
这是O ( n m 2 ) O(nm^2) O ( n m 2 )
发现n n n m m m
按题意的方法刷颜色的话,每次最多只会增加两块,也就是块的个数最多为2 m − 1 2m-1 2 m − 1
于是第一维只要枚举到2 m − 1 2m-1 2 m − 1
8-27 听了一些神仙题
要抓紧时间写完
8-28 Process 先搞了T2,然后写了T1,最后T3没调出来交了一个错的优化,结果获得了90分的好成绩
T1 [动态规划]
f [ x ] [ i ] f[x][i] f [ x ] [ i ] x x x i i i
g [ x ] [ i ] g[x][i] g [ x ] [ i ] x x x i i i
树上背包转移
T2 [分块]
以k k k
T3 [two pointers] [set]
固定左端点i i i j j j min x , y ∈ [ i , j ] ∣ a x − b y ∣ > j − i + 1 \min_{x, y\in [i, j]}|a_x - b_y| > j - i + 1 min x , y ∈ [ i , j ] ∣ a x − b y ∣ > j − i + 1
会更优
two pointers即可
需要用set维护那个min,一个维护当前状态,一个维护差值。这是个很经典的套路
一开始加入左右inf,可以简化代码细节
8-29 Process T1开场写了,T3想了个超级复杂的做法,搞了一上午搞出来了,T2暴力
T1 参见noip2018D1T1
T2 [动态规划] [计数]
发现< n m < n^m < n m > n m >n^m > n m < n m <n^m < n m n n n > n m >n^m > n m
于是只需要计算= n m =n^m = n m
n n n
具体转移看sol
T3 [概率和期望] [高斯消元] [换根DP]
我的做法:
考虑一个类似PKUWC随机游走的做法,设f [ i ] f[i] f [ i ] i i i f [ x ] = A [ x ] ⋅ f [ f a [ x ] ] + B [ x ] f[x] = A[x]\cdot f[fa[x]] + B[x] f [ x ] = A [ x ] ⋅ f [ f a [ x ] ] + B [ x ]
容易想到可以直接用线段树维护这个东西
但是对于不同的询问,每次A [ x ] = B [ x ] = 0 A[x] = B[x] = 0 A [ x ] = B [ x ] = 0
于是把询问离线,把询问挂在y y y dfs整棵树,一边处理询问
这样的话每次换根就只会有两个点的系数发生改变
正解:
考虑每条边的贡献(即这条边产生贡献的期望时间)
设f [ i ] f[i] f [ i ] i → f a [ i ] i\rightarrow fa[i] i → f a [ i ] g [ i ] g[i] g [ i ] f a [ i ] → i fa[i] \rightarrow i f a [ i ] → i
显然,f [ i ] = 1 d e g i + 1 d e g i ∑ j ( 1 + f [ j ] + f [ i ] ) f[i] = \frac{1}{deg_i} + \frac{1}{deg_i}\sum_{j}(1 + f[j] + f[i]) f [ i ] = d e g i 1 + d e g i 1 ∑ j ( 1 + f [ j ] + f [ i ] )
化简得到,f [ i ] = 2 ⋅ s i z e i − 1 f[i] = 2\cdot size_i - 1 f [ i ] = 2 ⋅ s i z e i − 1 g [ i ] g[i] g [ i ]
然后随便搞下就可以了