后缀自动机学习笔记
几次尝试学这个都没太搞懂,过几天就忘
今天看了一个讲得超级好的课件之后才真正理解SAM
趁热写一点笔记,省得以后又全忘了
可能大部分都是从ppt里搬来的吧。。。
UPD 20.1.31
今天复习了SAM
yyb的这篇文章 还写得挺好的
再举一个例子理解一下克隆节点的过程:
注:以下的内容(主要是定义)不一定非常严谨,但比较通俗易懂。而且大多数也只是自己对SAM的一点点感性理解,依旧不适合初学者阅读。。。
Brief Introduction
自动机,通俗来说,就是一张带有根和转移边的有向图,每条转移边上有一个字符,一个点出发的所有转移边上的字符必须两两不相同
考虑自动机上一条由根出发的由节点和转移边构成的有向路径,把路径的转移边上的字符按顺序拼接起来可以得到一个字符串 ,那么我们就说这条路径的终点(这是一个节点)接受字符串
如果一个自动机上存在一条由根出发的有向路径使得转移边上的字符按顺序拼接起来可以得到,那么我们就说被这个自动机接受
后缀自动机就是能接受某个串的所有后缀/子串的自动机
一些定义
节点/状态
后缀自动机一个节点/状态代表这个节点能接受的串的集合,一个节点内的所有串互相存在后缀关系(一个是另一个的后缀),且长度连续
right/endpos集合
一个子串在原串中所有结束位置构成的集合,SAM一个节点中所有子串的right集合相同
fa/parent/suffix link
SAM中一个节点所包含的所有子串可以看成是由最长的那个串不断删掉第一个字符构成的,但是有可能最短的那个串长度不为。那么这个fa就指向当前节点包含的最短的串删掉第一个字符这个串所在的节点
显然,从一个节点不断跳fa,就能遍历到所有它的所有后缀
并且,这样的后缀链接形成的parent树就是反串的后缀树
maxlen
一个节点所包含的最长子串的长度
构造
这里是一些关于构造的感性认识
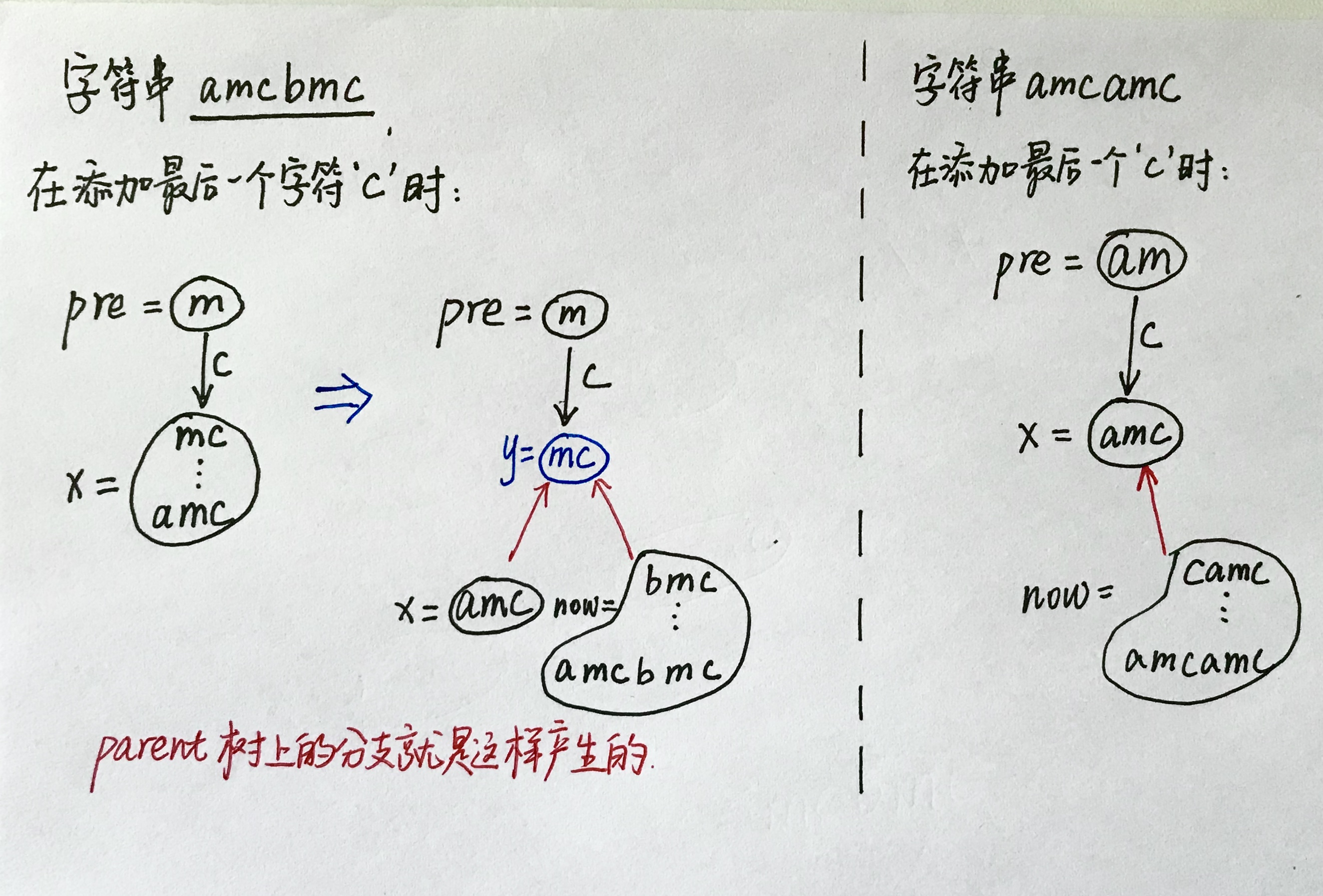
使用增量法进行构造,每次把之前存在的所有后缀都添上一个转移,转移到一个新的节点
其实上面一句话就把构造过程讲完了,下面只是一些细节
而之前存在的所有后缀显然就是上一次添加完的串的所有后缀,于是可以不断跳上一次添加的新节点的fa,添加它们到的转移
但是,有可能在跳fa的过程中,某个状态转移向当前字符的转移边之前已经出现(显然这种情况只会连续一段地出现,我们先只考虑最先出现的那个状态)
- 如果的
maxlen加上就等于转移到的节点(设为)的maxlen,则说明已经存在了连续一段的所有后缀了。也就是说,我们找到了一个能不重不漏地接受当前串所有后缀的节点集合。此时我们只需要把的fa[now]指向即可 - 否则,的
maxlen大于的maxlen + 1,这说明这个节点能接受的串太多了,而我们当前需要添加转移的只有小于等于maxlen + 1的那一部分。于是我们可以把这个点拆分,以maxlen + 1为界,把长度小于等于maxlen + 1的部分拆出来形成一个新点。那么fa[now]和fa[x]都要等于。并且的所有祖先原来有转移向的,现在都要改成向转移
时间复杂度,状态数,转移边数均可以被证明是级别的
状态数, 转移边数
Code
1 | int node_cnt = 1, last = 1; |
一些简单的性质
right集合
为了方便描述,我们称
传统节点为每次添加节点时像这样的节点,称克隆节点为每次通过拆分出来的,像这样的节点
后缀自动机的状态right集合大小是其在parent树中子树传统节点的数量,代表这个状态所表示的子串出现次数
原因很显然
匹配
后缀自动机上的匹配和KMP也差不多
因为KMP的一个状态是的一个前缀,所以它可以匹配到最长的为S的前缀的后缀
而后缀自动机的一个状态是的一个子串,所以它可以对的每个前缀求出最长的为S的子串的后缀
方法和AC自动机上跳fail是几乎一模一样的,只是这里变成跳fa。
具体来说,考虑每次新添加进来中的一个字符,如果当前状态有的转移边则匹配成功;否则不断跳fa直到匹配上或者跳到根节点
还有一些具体的应用还是单独再写一篇吧
这篇文章(可能会?)持续更新